Newscorp is indeed dropping out of Google
01 Dec 2009The big disappearing act
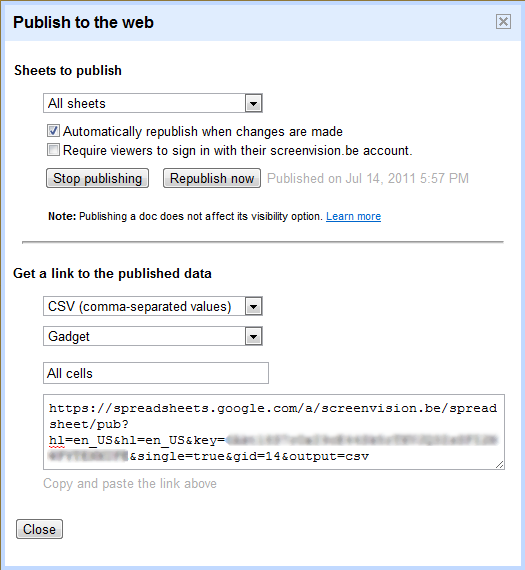
When Rupert Murdoch announced that he would remove his sites from Google (in order to make a deal with Microsoft, so that only Bing would have the NewsCorp pages, as we now assume), he apparently wasn’t kidding. Although all Google web sites still indicate that e.g. MySpace has 179 million pages in the index, the Google API is currently returning another number for that: only 7 million. The total number of NewsCorp pages (a sum of MySpace, IGN, RottenTomatoes, …) has dropped from 192 million to 12 million.
Which sites are Newscorp?
Let me give you some of his ‘big’ sites and how their # indexed pages have dropped:
- Myspace: from 179 mio to 7 mio
- RottenTomatoes: from 4 mio to 100.000
- IGN: from 4 mio to 300.000
- Stats.com: from 2.4 mio to 50.000
- News.com.au: from 1.2 mio to 70.000
- Sky.com: from 1.4 mio to 85.000
I suspect the Fox, National Geographic, Daily Telegraph, and other sites will soon follow.
Did he send in the robots?
I checked to see if NewsCorp finally started using the robots.txt file, because that’s the way you’re supposed to remove content from Google, not with press conferences.
Myspace:
User-agent: * Disallow:
RottenTomatoes:
User-agent: Mediapartners-Google Disallow:
And the answer there is “no”. So I’m not sure how they tell the Google crawler to stay out.
— UPDATE —
Source of the data:
The numbers come from http://tools.forret.com/newscorp/, which uses the Google Search API. I double-checked the replies from the API: for MySpace.com I get "estimatedResultCount": "6950000" so 7 million, not 179 million. If there’s an error, it’s in the Googleplex.